Mark Potanin | AIcrew Stories
 By
snehananavati
By
snehananavati

Welcome back to our new series of AIcrew Stories! 🎉
In this corner of AIcrowd, we will be sharing inspiring stories and insights from top AIcrowd participants. ✨
We hope these deep-dives with the participants will help you in your own Machine Learning journey.
👋 In the second episode of AIcrew Stories, Vrushank from AIcrowd met up with Mark Potanin, one of the runner-ups of Round 3 of the Food Recognition Challenge.
Mark works as a data scientist at Sberbank, one of the biggest banks in Russia. He is also a PhD candidate in Computer Science at Moscow Institute of Physics and Technology. He is investigating non-trivial approaches for neural-networks employing Neural-Architecture Search (NAS)
The Food Recognition Challenge was the first competition on AIcrowd’s platform that Mark participated in.
💪 Getting Started with the Challenge
On asking why he chose this problem, he said, “Between my PhD and work, I don’t have much time to improve my skill. I found this to be an interesting problem and so decided to take part in it. I have been working in the field of Data Science for over three years now.
Last year, I took up some projects in Computer Vision and this competition was my first challenge in the field of Computer Vision.” He said that the Food Recognition Challenge was unique. “I have seen segmentation tasks on other platforms but did not find them interest as they would have a small dataset. This challenge has a huge dataset along with a large number of classes and that made it very interesting.”
We asked Mark if he was particularly interested in instance segmentation. He said, “I have previously created models for segmentation and detection tasks so I was familiar. There are a lot of cool models that exist for object detection but very few models for segmentation detection.”
🔬 His Approach
Mark's devoted efforts for this challenge led him to spend around 5-6 hours every day for two weeks on this problem. According to him, he didn’t spend much time investigating a new approach or searching for unique models. Instead, he focused his time and efforts on training the model he made. His reason being, “Earlier in the competition, I spend a lot of time trying different approaches and the score didn’t really improve, which is normal in Machine Learning.” When asked for his plans for round 4, Mark said, “I’ll create a new approach once the new dataset gets published. This time, perhaps, I will try a smaller, less memory consuming model. I think it is smarter to create ensemble models to solve this challenge.”
🚧 Encountering Obstacles
According to Mark, the main obstacle in this challenge was the limit on GPU memory assignment. This made running ensembled models tricky. Often one model consumed all the time, leaving not enough time for the second model to run.
👀 Looking Around
Given that Mark is one of the top participants, we asked him to share his impression of fellow leaderboard toppers. He was impressed by other participants, especially Eric, who made around 400 submissions for this challenge. Mark found Eric’s efforts relentless. He echoed the need for knowledge sharing among top participants on the platform. [You can read more about Eric’s solution, approach and moreover here]
👨💻 Mark’s Advice For You
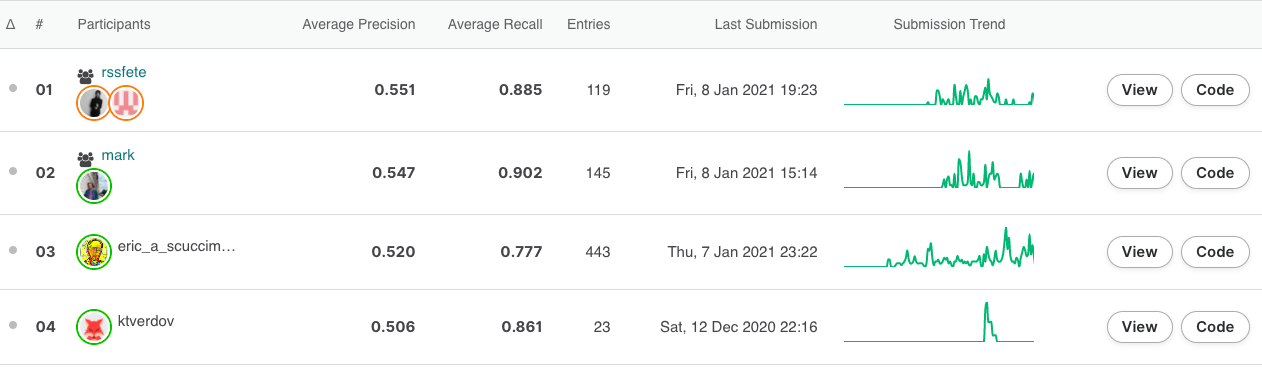
With an AP score of 0.547 and an AR score of 0.92, Mark has some advice for fellow participants looking to improve in this challenge. He recommends playing with the model’s inference settings and tweaking the segment detection model. This often helps in improving the score. While starting such a challenge, he says, “You have to look at two things. One, how the model works in real life. Manually visualise how the food items are being boxed. It needs to look fine. Secondly, the score for the model. Since the competition evaluates scores it is also necessary to make sure you get a good score.” To further improve the metrics he suggested, “Train the models and set a lot of masks and boxes from inference settings. It may not look good but it does the job. I recommend tweaking the model settings for inferences and test time for augmentation approaches.”
When not working as a data scientist or on his PhD, Mark likes to unwind by playing videogames. He recently purchased Cyberpunk 2077 but like many of us, he too disliked the bugs in the game. In his free time, he likes to read papers on data science, drink and dance in the bar. Check out Mark’s profile.
If you liked this, you’d also enjoy the interview with fellow runner-up Eric Scuccimarra over here.
Comments
You must login before you can post a comment.
You may also like...

 aryankargwal
snehananavati
aryankargwal
snehananavati