
 UA
UA
Activity
Challenge Categories
Challenges Entered

Automating Building Data Classification
Latest submissions
See All| graded | 279853 | ||
| graded | 279798 | ||
| graded | 279778 |

Small Object Detection and Classification
Latest submissions

Audio Source Separation using AI
Latest submissions

Using AI For Building’s Energy Management
Latest submissions
See All| graded | 204303 | ||
| failed | 204246 | ||
| failed | 203814 |

Machine Learning for detection of early onset of Alzheimers
Latest submissions
See All| graded | 138624 | ||
| graded | 138610 | ||
| graded | 138045 |
| Participant | Rating |
|---|
| Participant | Rating |
|---|
-
Chio-Chio-San Brick by Brick 2024View
NeurIPS 2022: CityLearn Challenge

Submission waiting in queue
About 2 years ago@kingsley_nweye hi, just in case - it looks like the submission process is super slow (for eg my entry after the fix is already evaluating for 3 hours and is still not finished), + I see no updates on the leaderboard from any team. Is it expected ?
Submission waiting in queue
About 2 years ago+1 would be great if someone will check it asap so that we would have last 2 days of the competition available for submissions
Phase 2 episode count and timeout update
Over 2 years ago@mt1 sadly it does not make any sense now singe we already know what happens during the year. Ideally we should discuss hiding future months only if the orgs have more data somewhere))
[Announcement] Update to Evaluation and Leaderboard
Over 2 years agoHello!
A small suggestion to the ramping part of the grid cost
-
with the current implementation you don’t encourage a smooth load change. As an example here is an image with 3 load patterns, all consume the same amount of energy, and the ramping is A: 8, B:16, C: 8. In other words it is the same for buildings A and C, while I expect C is much more preferable for the grid.
-
a very simple adaptation in your formula is to take changes in load to the power of 2 instead of the absolute. Later, if needed, you can take a square root of the result, which will make the ramping as A: 4, B:5.7, C: 1.3.
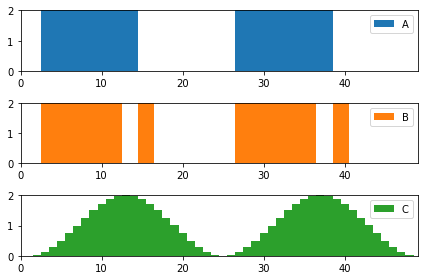
In any case here is the code for the example if you want to check:
import pandas as pd
import numpy as np
a = pd.Series(np.zeros(shape=48))
a[2:14] = 2
a[26:38] = 2
b = pd.Series(np.zeros(shape=48))
b[2:12] = 2
b[14:16] = 2
b[26:36] = 2
b[38:40] = 2
c = pd.Series(np.sin(np.arange(-np.pi*0.5,np.pi*3.5,np.pi/12))+1)
df = a.to_frame('A').join(b.to_frame('B')).join(c.to_frame('C'))
df.index+=1
df.loc[0,:] = 0
print((df-df.shift(1)).abs().sum())
print((df-df.shift(1)).pow(2).sum())
print((df-df.shift(1)).pow(2).sum()**(0.5))
Phase 2 episode count and timeout update
Over 2 years agoIf I may, I’d add some proposals to the evaluation before the phase 3 has started:
I see the competition problem in 2 parts:
- how to know the future
- how to act when you somehow figured out the future
In my opinion, the ideal test would be an unseen set of buildings in the unseen time in the future. Relating it to our competition, if we’d design it from the beginning and if you only have 1 year of data from 17 buildings: it would be great to for example give first 8 month and 10 buildings for training / public scores and have the next 4 months 7 buildings for private scores, and not to show the scores/logs for the private part until the end. Of course only one episode of evaluation should be run.
However, when all the future data is already shown, I think the best design of the 3rd stage is to:
- run it only for 1 first episode - this would eliminate the problem of overfitting/memorising data, you will not even need to check who is doing what + in reality you will never have a chance to be twice in the same time, why do it in the evaluation?
- do not show scores for additional 7 buildings and have a final score only on them (as on a separate 7 building community): this will eliminate the manual/ other solutions that overfit on training, or the data from logs in phase 2. + Blocking logs as described in the previous post is mandatory.
This are only my ideas, would be glad to see the organisers and participants responses / proposals.
Weather Data "Predictions"
Over 2 years agoIf we simplify a lot, pv generation should be very correlated with solar irradiance. However, in our case, solar irradiance does not match to pv power almost at all. Will dm more details.
Weather Data "Predictions"
Over 2 years agoHello @kingsley_nweye ! Is it possible to check if the weather file is from the same location/time as our buildings in stage 1? For me it looks wrong…
ADDI Alzheimers Detection Challenge
👋 Welcome to the ADDI Alzheimer's Detection Challenge!
Over 3 years agoDo not worry, I also root for an honest competition  I’ve sent my thoughts on how the current competition design may be cheated and how it could be improved. I believe that scoring on the private data only is a great step and solves some of the problems. Let’s see if other improvements will come as well.
I’ve sent my thoughts on how the current competition design may be cheated and how it could be improved. I believe that scoring on the private data only is a great step and solves some of the problems. Let’s see if other improvements will come as well.
👋 Welcome to the ADDI Alzheimer's Detection Challenge!
Over 3 years agoHello everyone, please tag me if you are referring to my submissions, it is hard to keep track of all the forum.
I want to raise a point, that most ML competitions are very far from production-grade code, and are focused on a single goal - optimize scoring metric (if they overfit, do not generalize, etc - this is not a problem for participants if the goal is achieved). The host on their hand gets all the interesting ideas that were generated during the competition.
If an organizer wants to prevent leakage, and make the competition fairer, steps are done in advance by designing the competition itself. You can’t just leave a private target somewhere and say “guys don’t use it, it’s against rules”.
So it is very strange to see a sentence “Entrants engaging in leaderboard probing will be disqualified”, when most of the participants submitted “all 0, all 1 scores” to figure out public class distribution. Leaderboard probing is a part of the competition, people fine-tune models, class balancing, and probabilities post-processing when you use the public score as feedback is a probing. Could someone please give a robust definition of probing?
Why do we need scoring on the 100% of test data, when it creates that many problems?
add: overall I believe that it would be great if clear rules are established (that are reasonable for participants, aicrowd, and the host), and we compete within these rules. As opposed to “everyone interprets rules as they want, the host decides if winners are eligible in the end”.
Submission rules
Over 3 years agoHello team =) Could you please respond or tag a person to whom these questions should be addressed?
Submission rules
Over 3 years ago- How do we select our final submissions? (in case we believe private test set is different from public test set)
- What are the time constraints on submission stages? (training, inference)
- it is said that “Note: The scores used to compute the current leaderboard are tentative scores computed on 60% of the test datasets. The final scores, computed on the complete test datasets, will be released at the end of the competition.” so will the final standings be based on 40% or 100% of the test set? Is ti correct that now we see the scores from 60% of 1473 samples?
Submission error
Over 3 years agoThank you, @ashivani ! This did help, and I made several successful submissions.
Now I have another problem and I wonder if you could maybe point where to search for the problem.
I’m getting AttributeError: '_name_of_the_model' object has no attribute 'classes_' during the inference stage. This error may happen if the classifier is not fit, however it is strange since the notebook works fine before submission, and the model is loaded from assets.
Submission error
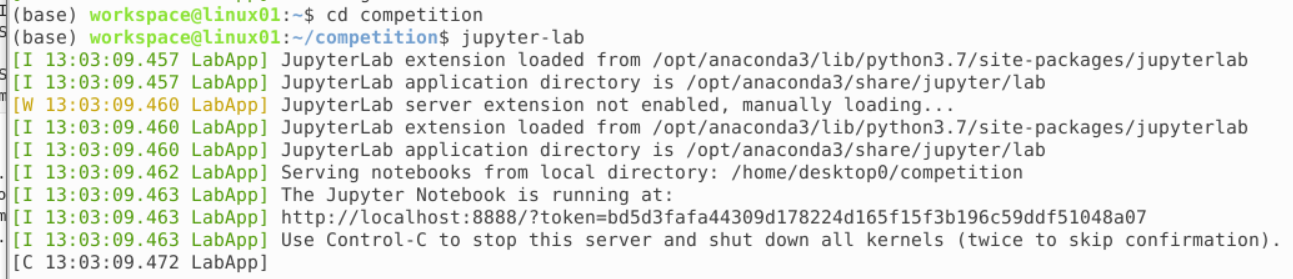
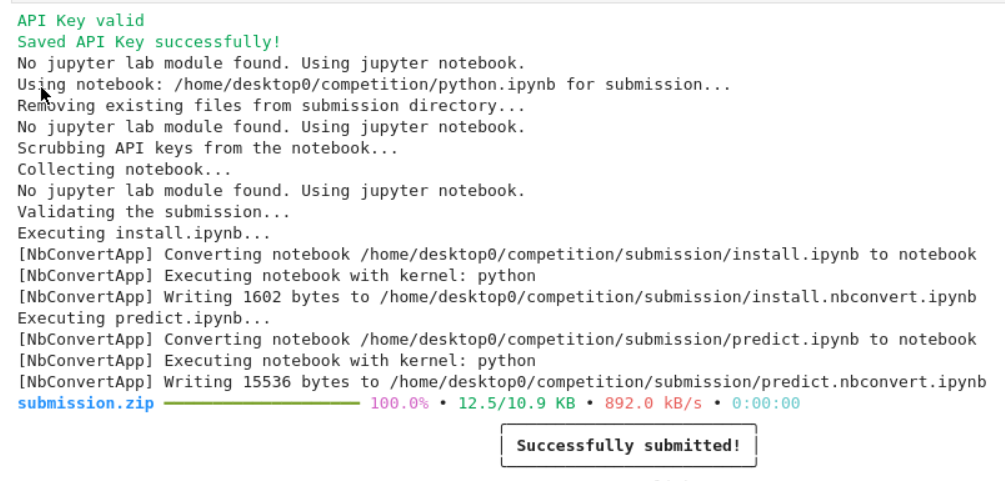
Over 3 years agohello everyone!
I’m using linux VM, and have troubles with submission.
my steps:
-
launch jupyter lab inside my working folder:
-
specify path variables as follows:
-
submit:
-
however submission fails:


long error log in details, and:
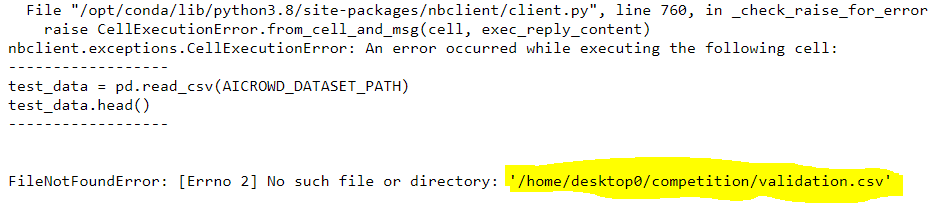
5.so what do I do if I have this file:
Is there an expected date for results release?
About 2 years agointeresting to know when will we see the private results